Protecting Unity's IL2CPP builds
When someone mentions Unity game engine, the first thing that comes to most people’s mind is either the splash screen, the plethora of asset flip mobile games, or the recent licensing controversy. If you are into game security though, Unity implies an easy target, and you most likely think of Cheat Engine’s Mono Dissector, dnSpy, and all sorts of IL2CPP tools.

Unity’s splash screen
Mono
Unity uses C# as its primary language, and it has two scripting backends for you to choose from: Mono and IL2CPP.
When Mono is used, the compilation process is exactly as you would expect for any other .NET project: the scripts get compiled into .NET assemblies (IL), and then the Mono runtime is shipped with the game, which does the actual JIT machine code compilation and execution.
The thing about .NET assemblies, though, is that you can just open them in any .NET decompiler tool (like dnSpy), and you will get almost 1:1 code reconstruction from the original. On top of that, you can also very easily patch the code by simply recompiling parts of it.
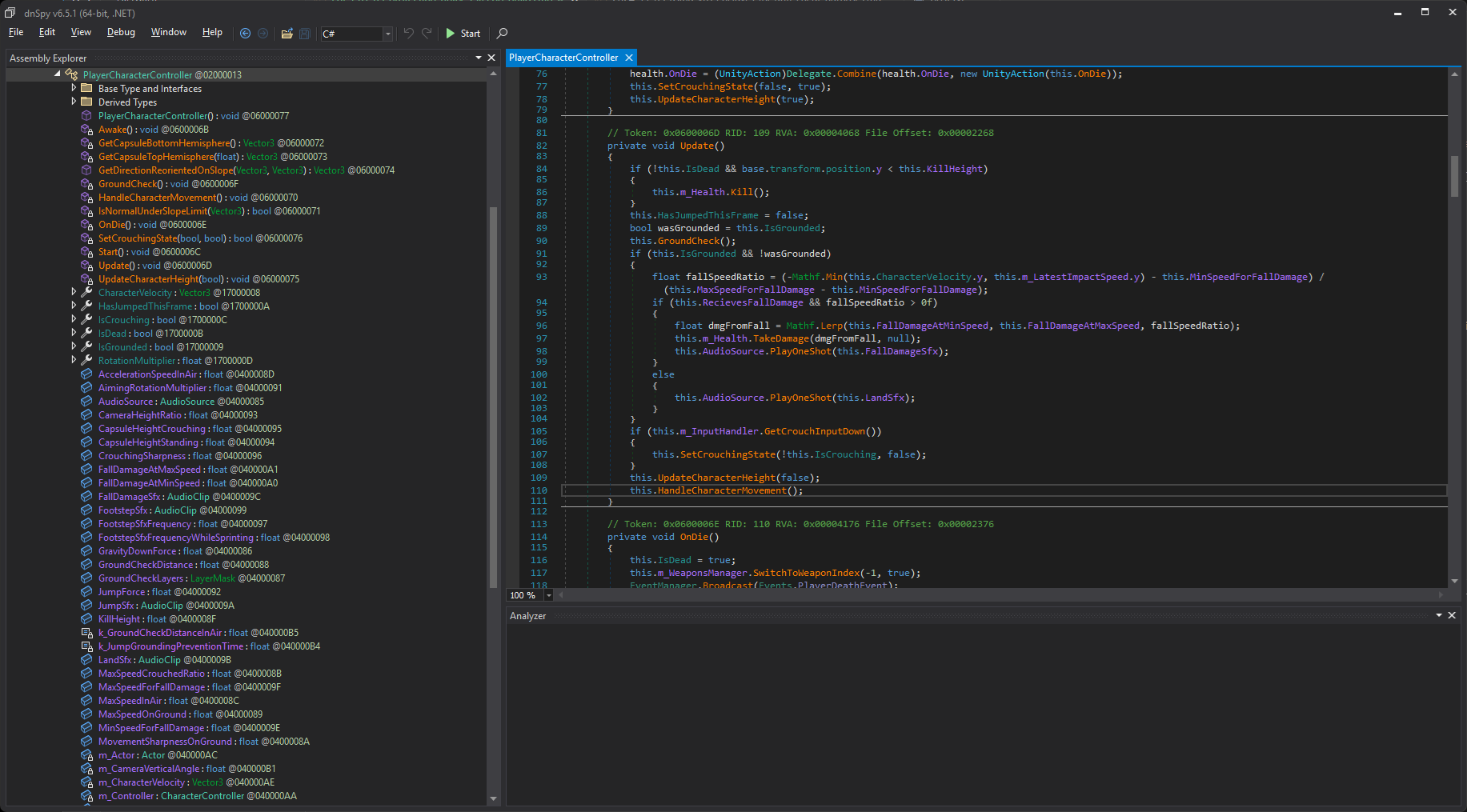
dnSpy decompiling function from sample FPS microgame
This is not really a problem if you are making a single-player game and you want to allow your players to mod the game to their heart’s desire. There are even projects that streamline this process, and some developers even opt to integrate them into their game builds directly.
When it becomes a problem is when you are working on some sort of competitive multiplayer game. You definitely don’t want players to be modding that, and you want to preferably make it as hard as possible to reverse-engineer it.
So, what are your options? If you are using the Mono backend, then unfortunately not much. Some tricks I will show later will work there too, but realistically, your best bet is some off-the-shelf .NET obfuscator. Also, due to the JIT compilation, there is no way for you to verify the code integrity once the game is running. A malicious actor can simply overwrite the JITed machine code, and you have no reference to compare it to. That’s not the focus of this article, though, so let’s move to IL2CPP.
IL2CPP
The documentation regarding IL2CPP states the following:
The IL2CPP (Intermediate Language To C++) scripting backend is an alternative to the Mono backend. IL2CPP provides better support for applications across a wider range of platforms. The IL2CPP backend converts MSIL (Microsoft Intermediate Language) code (for example, C# code in scripts) into C++ code, then uses the C++ code to create a native binary file (for example, .exe, .apk, or .xap) for your chosen platform.
Well, that sounds like it completely solves the problem, no? Mono assemblies get somehow magically translated to C++ code, which is then compiled into a native binary. No .NET is involved past that point, so unless we ship debug symbols with the game, reverse engineering of the game should be significantly harder, and it should be impossible to recover any class, method, fields, or parameter names, right?
Unfortunately, no. IL2CPP was not designed as a system to better protect the game’s code and not even to improve performance (as some people might think), but rather for Unity to be able to run on platforms where JIT compilation is not allowed or viable.
To make matters worse, Unity uses a component-based architecture. In this system, individual scripts (C# code files) are attached to GameObjects, which are organized into scenes. Due to this, the compiled scenes (and other assets) include information about which scripts are attached to which GameObjects. This is done by referencing classes, methods, and fields by name, which in turn means that this information has to be retained by the scripting backend as well. For example, when the engine asks for PlayerCharacterController to be initialized for a GameObject, it needs to know which class it is.
As you can imagine, there are automated tools that can leverage this information. The most popular one is most likely Il2CppDumper. Let’s check how it works.
I have created a new project using the FPS microgame template in Unity 2022.3.55f1, changed the scripting backend to IL2CPP and made a Windows build.
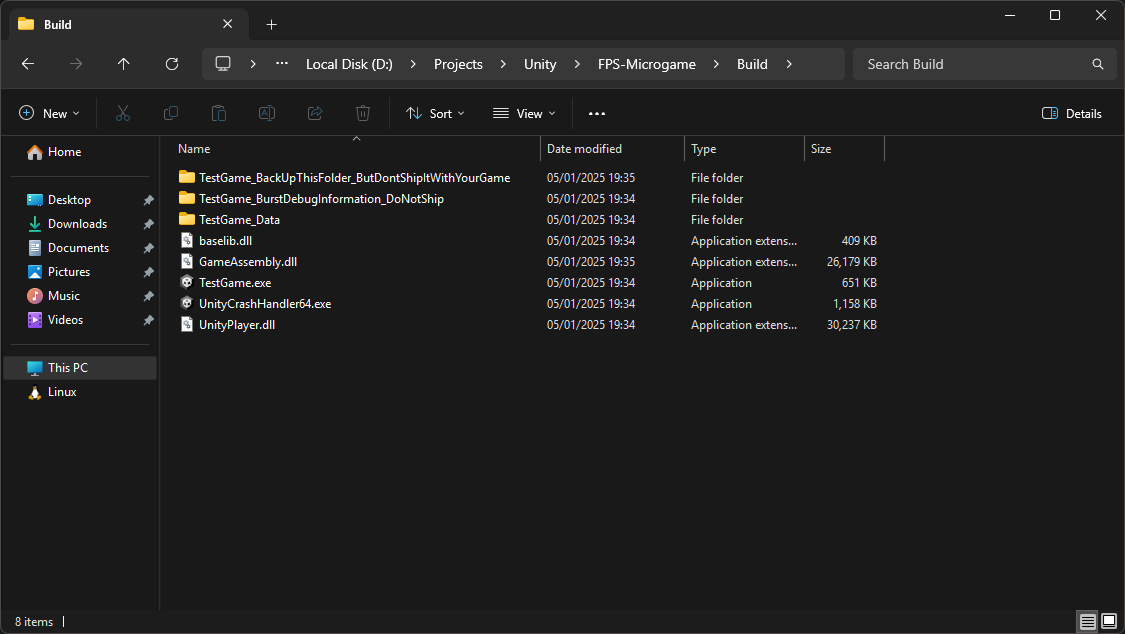
The structure of the folder is as follows:
- Two folders containing debug symbols and managed assemblies used by IL2CPP. These files are not intended to be published with the game build.
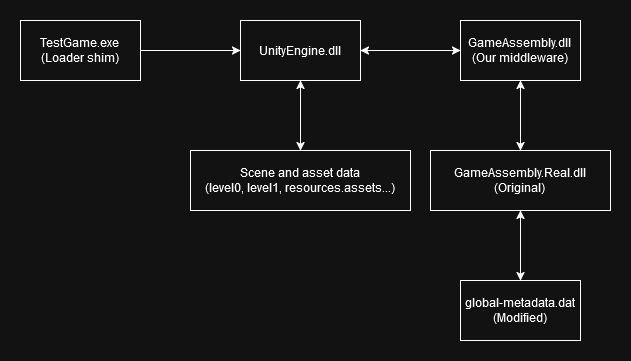
TestGame_Data: Contains compiled scenes, asset information, and IL2CPP metadata (we will cover this later).baselib.dll: An IL2CPP base library providing platform-specific implementations for file I/O, memory allocation, networking, and threading.GameAssembly.dll: Includes the actual game code compiled from the C++ generated by IL2CPP.TestGame.exe: A loader stub responsible for loadingUnityEngine.dll.UnityEngine.dll: Contains the game engine code.
Now let’s try running the previously mentioned Il2CppDumper. All we have to do is specify the correct files as command-line parameters and run it.
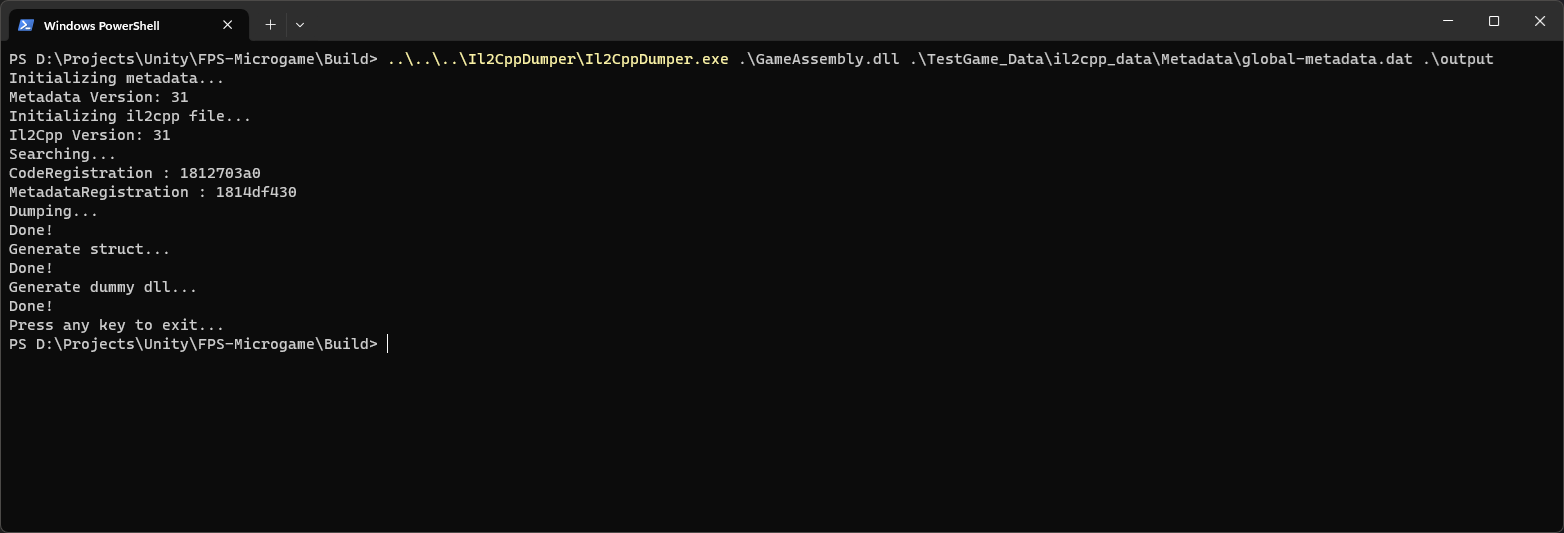
This will generate several files. The main one is dump.cs, which contains information about all classes, including their fields and methods with their full names reconstructed. It also contains in-memory offsets to these elements, which makes it incredibly easy to modify them if you know where their class instance is in memory.
On top of that, there are also reconstructed .NET assemblies, which also include all the function names, parameters, fields, etc., except for the actual code logic in those functions.
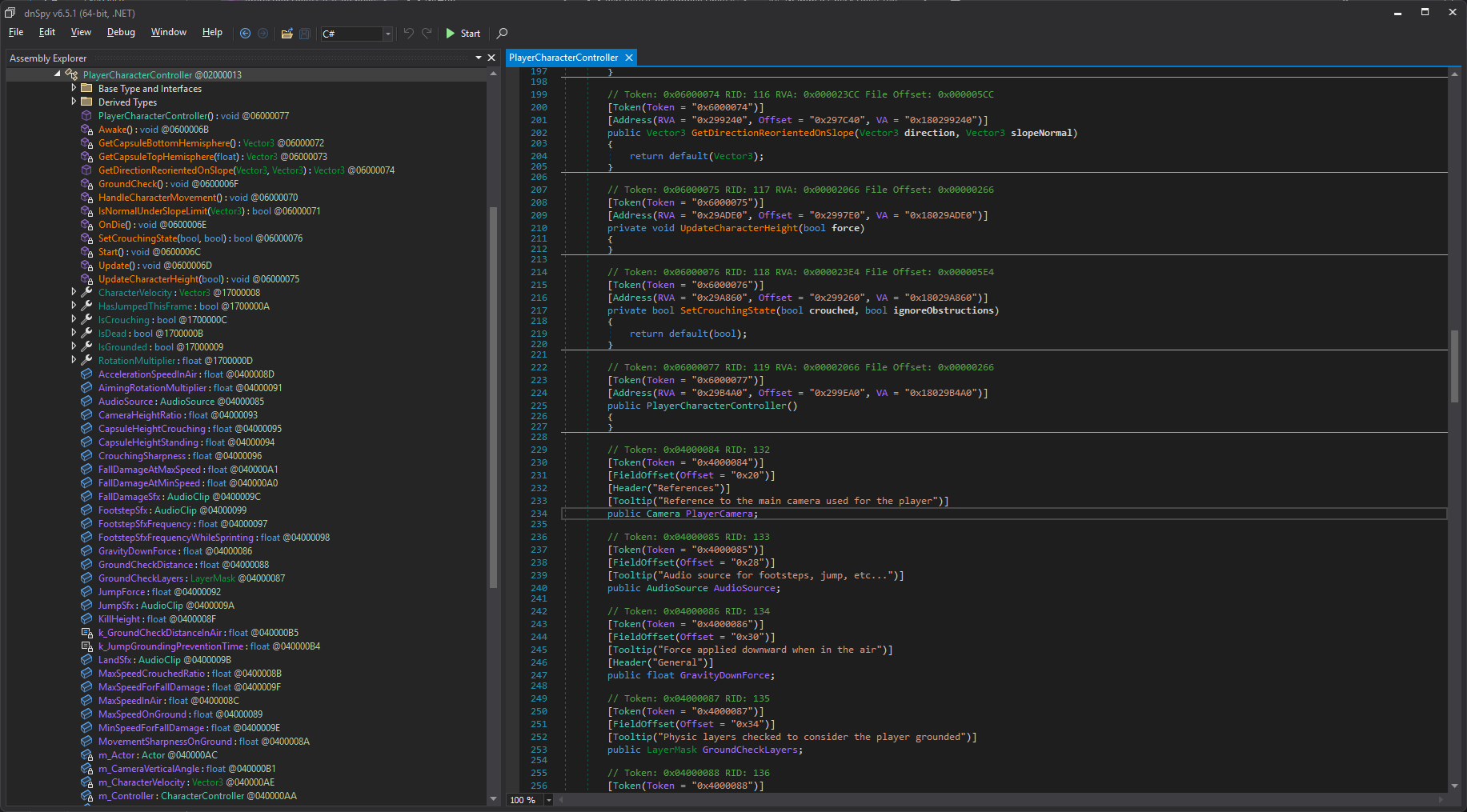
If you wanted to write a cheat that would overwrite the gravity in the game while it’s running, all you would have to do now is find GameObjectManager in UnityEngine.dll (which is quite trivial given that Unity has a public debug symbol server), then use it to loop through the active game objects to find one with the PlayerCharacterController class, and then use the GravityDownForce offset you’ve just got from the dumper to overwrite the value.
Experimenting
Congratulations 🎉, now that the mandatory introduction is out of the way, we can get to the fun stuff. Most of the information that the dumper is reading is not stored in GameAssembly.dll, as you might expect, but in global-metadata.dat located in the TestGame_Data\il2cpp_data\Metadata directory.
Let’s experiment a bit and mess around with a hex editor (HxD in my case). What happens when we replace the previously mentioned GravityDownForce class field name with something else of the same length?
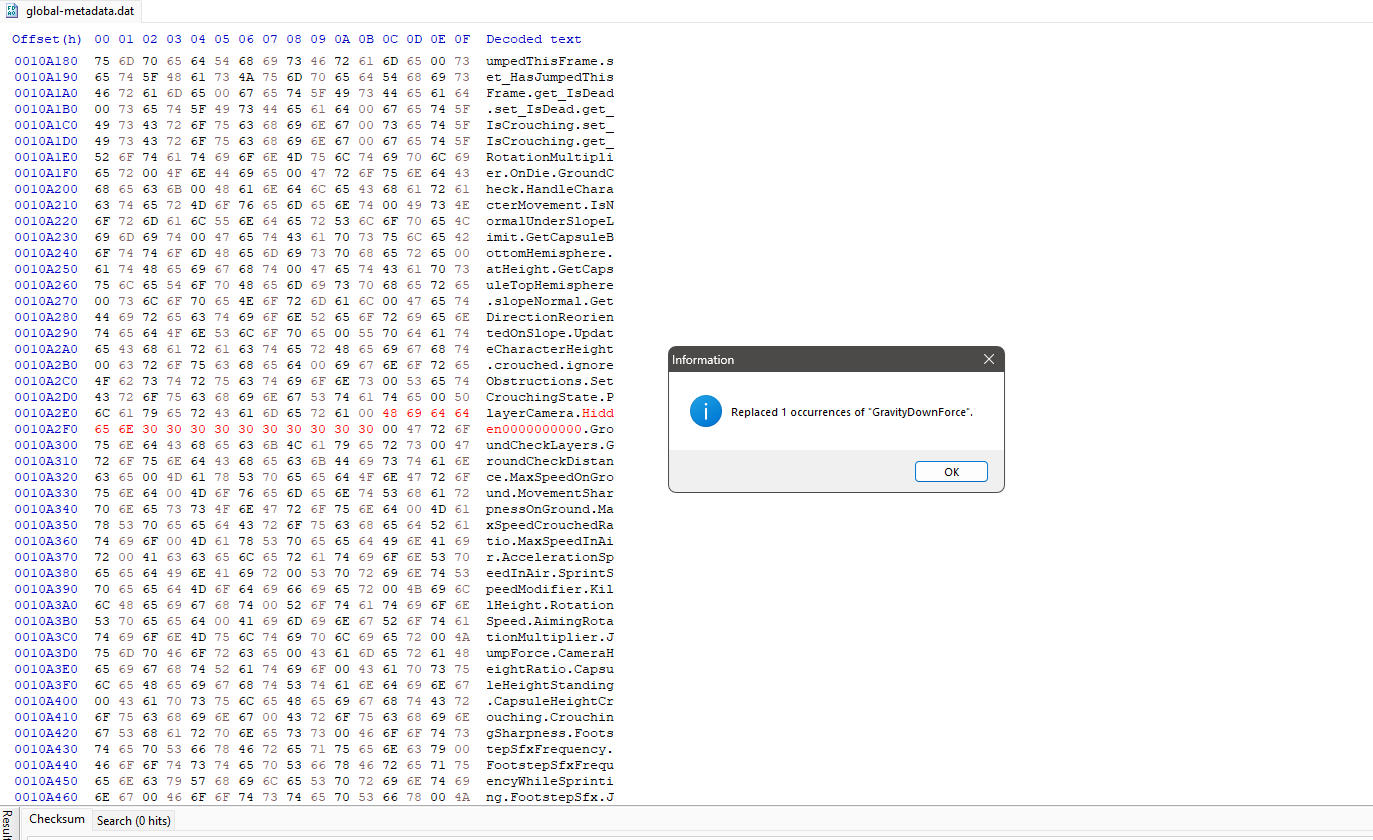
Now let’s try running the game.
Surprise, surprise, it runs perfectly fine. What if we run the dumper now?
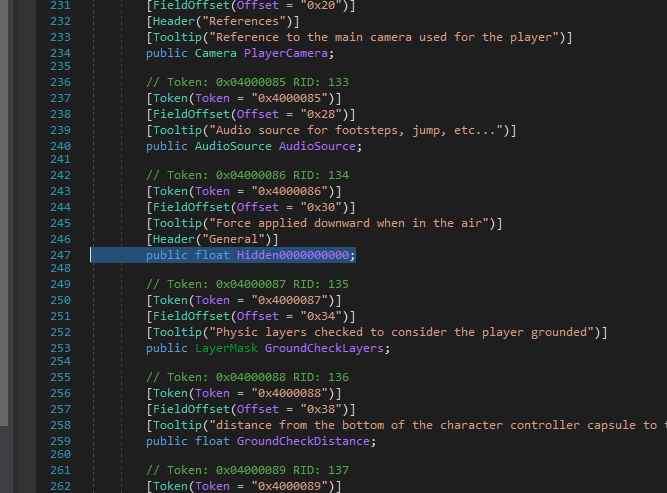
So it’s that easy? Just do string replacement in the file and voilà, names obfuscated? Well, I wouldn’t be writing this article if it was that easy, would I? Let’s replace something else, like the PlayerCharacterController class.

The game launches, but it’s broken. If we look into the log (Player.log), we can see many null reference exceptions being thrown on each frame.
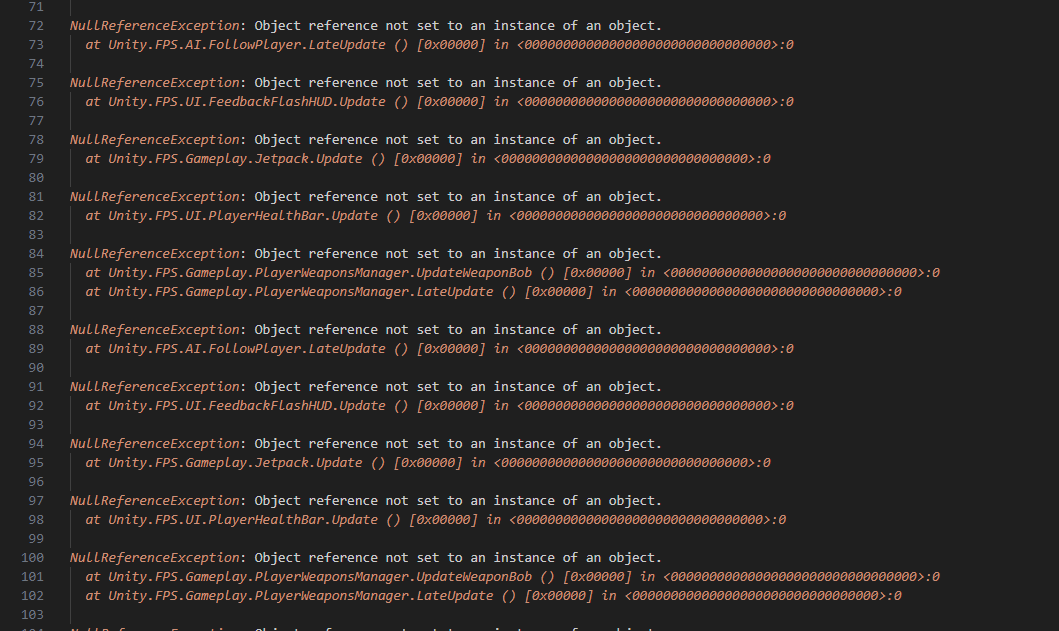
This is due to the previously mentioned component-based architecture. The engine wants to associate the script with the name PlayerCharacterController to the player GameObject, but that fails since there is no class with this name anymore. Other scripts fail too, as they expect the class to be present on the GameObject as well.
Now what?
In theory, it should be possible to replace all the names in both the compiled scenes and assets and in global-metadata.dat, which would be optimal since the original names would not be present anywhere in the build. In practice, though, that would mean reverse-engineering and parsing those scenes and asset formats so that you could properly do the replacement. Basic text find and replace would work only if we had super specific names (like OBFUSCATE_THIS_PlayerCharacterController); otherwise, we might end up in a situation where our class is called just Player, and replacing this string would break the entire engine.
Lets try to take a safer, more minimal approach. We will only change type names in global-metadata.dat and keep the original ones in scenes and assets.
But how do we do that without breaking the game? Instead of using completely random names, we will create a hash from them so that if we have the original name, we can easily get the corresponding hash, but not the other way around. We will then use a middleware DLL library that will act as GameAssembly.dll, redirecting most of the calls to the real library without modifying them. However, for calls that take type names as input, we will apply the hashing function to those inputs first before forwarding the call to the real library.
global-metadata.dat
To parse global-metadata.dat, we can either look at the code of the previously mentioned Il2CppDumper, Unity’s debug symbols, or directly at the source code of GameAssembly.dll. To do that, we will build our test project again, but this time, check the option “Create Visual Studio Solution.”
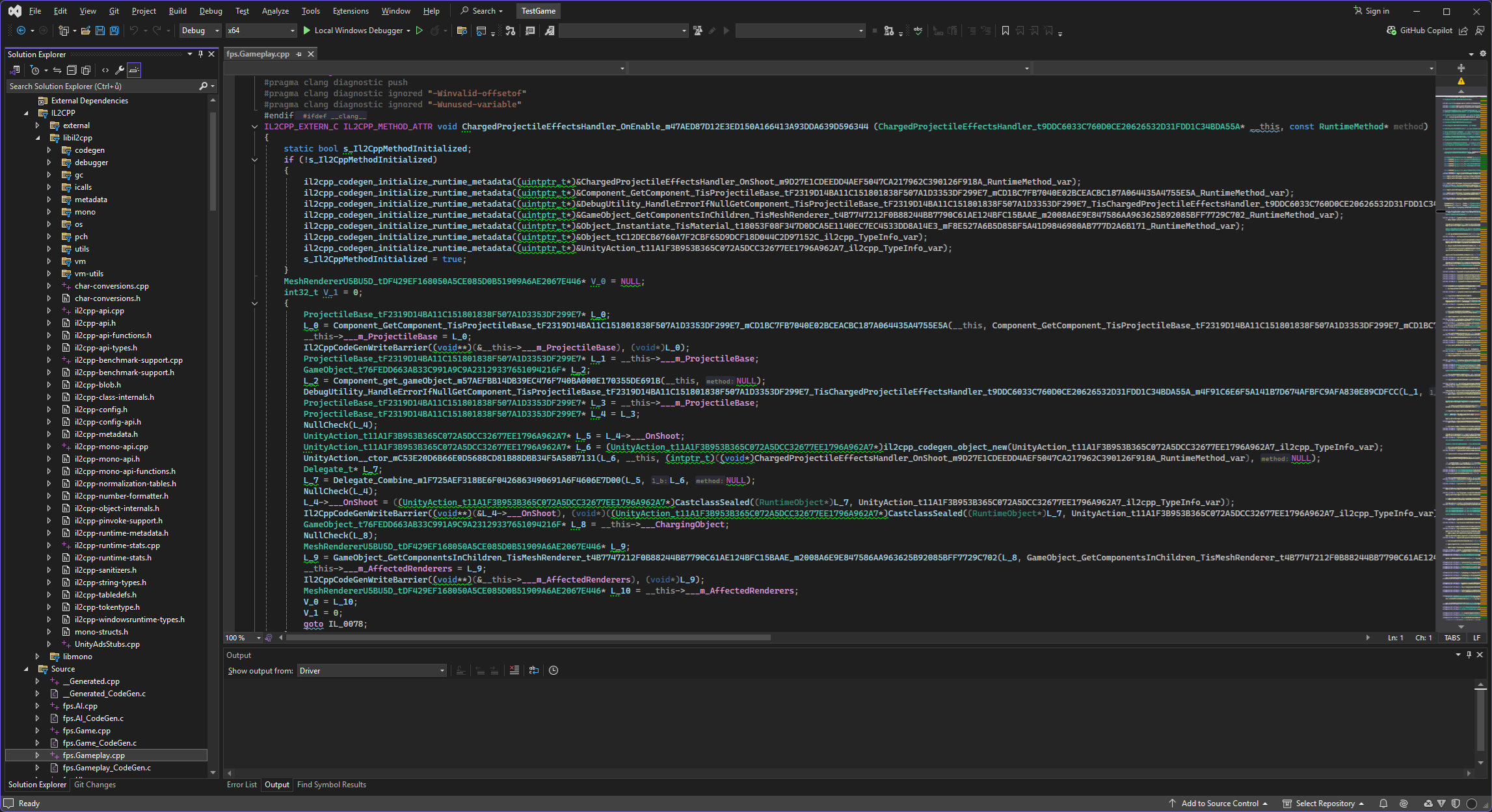
The created solution contains both the code generated by the IL2CPP compiler and all the supporting code of the IL2CPP runtime library.
Hold on
So we can get the whole source code of the GameAssembly.dll file. Why would we then be messing with some additional DLL? Why not edit the source code directly and just compile it? Is there something stopping us from doing so?
Good question. Yes. The Unity licensing team. Unless you have an enterprise license, which can give you access to the engine source code, you are not allowed to modify it.
If your game studio does happen to have permission to modify it, you can implement the middleware library code directly into it. Although, at that point, you could make much more advanced modifications to the engine build process itself.
Back to global-metadata.dat
If you are interested, you can go through the code to see exactly how global-metadata.dat is loaded and used. For our intents and purposes, though, all we need is a way to parse the file to hash selected type names.
The file structure is incredibly simple. It has a header with offsets to individual definitions and their count:
typedef struct _Header
{
uint32_t Sanity;
uint32_t Version;
uint32_t StringLiteralOffset;
uint32_t StringLiteralSize;
uint32_t StringLiteralDataOffset;
uint32_t StringLiteralDataSize;
uint32_t StringOffset;
uint32_t StringSize;
uint32_t EventsOffset;
uint32_t EventsSize;
uint32_t PropertiesOffset;
uint32_t PropertiesSize;
uint32_t MethodsOffset;
uint32_t MethodsSize;
/* ... */
} Header;
typedef struct _FieldDefinition
{
uint32_t NameIndex;
uint32_t TypeIndex;
uint32_t Token;
} FieldDefinition;
typedef struct _PropertyDefinition
{
uint32_t NameIndex;
uint32_t Get;
uint32_t Set;
uint32_t Attrs;
uint32_t Token;
} PropertyDefinition;
/* MethodDefinition, TypeDefinition, ... */
Getting the individual definitions and strings by their index can then be done like so:
template<typename T>
inline T Offset(size_t sectionOffset, size_t itemIndex)
{
return reinterpret_cast<T>(reinterpret_cast<uint8_t*>(header) + sectionOffset) + itemIndex;
}
inline char* GetStringFromIndex(uint32_t index)
{
return Offset<char*>(header->StringOffset, index);
}
inline TypeDefinition* GetTypeDefinitionFromIndex(uint32_t index)
{
return Offset<TypeDefinition*>(header->TypeDefinitionsOffset, index);
}
/* GetParameterDefinitionFromIndex, GetMethodDefinitionFromIndex, ... */
Before we go through them and start hashing the names, we need to decide what hashing function we will use. The function should be as fast as possible and preferably able to run without any additional memory allocations.
After searching for roughly 3 seconds, I found xxHash, which appears to be exactly what we need.
For the purposes of this article, I wanted to make it as simple as possible. To avoid moving the entire file around and adjusting all offsets, we are going to replace the names with their hashed counterparts but make the hash the same length.
To do this, we will use this helper function. It uses xxHash to generate a 64-bit number from the buffer, then converts it into a hexadecimal string, which is either cut or repeated depending on the needed length. No standard library functions (such as std::format) are used to maximize performance and limit the aforementioned memory allocations, as we are going to reuse this function in the middleware DLL, so it will be called quite often.
void Hash::Run(char* buffer, const size_t size)
{
constexpr auto seed = 0x59648347113887;
const XXH64_hash_t hash = XXH64(buffer, size, seed);
static const char* hexDigits = "0123456789abcdef";
char hashString[17];
for (int i = 0; i < 8; ++i)
{
hashString[i * 2] = hexDigits[(hash >> (56 - i * 8)) & 0xF];
hashString[i * 2 + 1] = hexDigits[(hash >> (52 - i * 8)) & 0xF];
}
hashString[16] = '\0';
for (size_t i = 0; i < size; ++i)
buffer[i] = hashString[i % 16];
if (size < 16)
buffer[size] = '\0';
}
Now let’s get to the hashing. We will first get all the types and then retrieve their fields, methods, and properties. We’ll also perform a sanity check to ensure that the file is indeed a metadata file.
void Metadata::ModifyType(TypeDefinition* type)
{
char* namePtr = GetStringFromIndex(type->NameIndex);
std::string name(namePtr);
if (IsInternalType(name))
return;
if (!Config::ShouldProtect(namePtr))
return;
Hash::Run(namePtr, strlen(namePtr));
printf("%s => %s\n", name.c_str(), namePtr);
for (uint32_t i = 0; i < type->FieldCount; i++)
{
FieldDefinition* field = GetFieldDefinitionFromIndex(type->FieldStart + i);
ModifyField(field);
}
for (uint32_t i = 0; i < type->MethodCount; i++)
{
MethodDefinition* method = GetMethodDefinitionFromIndex(type->MethodStart + i);
ModifyMethod(method);
}
for (uint32_t i = 0; i < type->PropertyCount; i++)
{
PropertyDefinition* property = GetPropertyDefinitionFromIndex(type->PropertyStart + i);
ModifyProperty(property);
}
}
bool Metadata::Process(std::vector<uint8_t>& buffer)
{
header = reinterpret_cast<Header*>(buffer.data());
if (header->Sanity != 0xFAB11BAF)
return false;
printf("Version: %u\n", header->Version);
typeCount = header->TypeDefinitionsSize / sizeof(TypeDefinition);
printf("Types: %u\n", typeCount);
for (uint32_t i = 0; i < typeCount; i++)
{
TypeDefinition* type = GetTypeDefinitionFromIndex(i);
ModifyType(type);
}
return true;
}
Notice how there is the IsInternalType() and Config::ShouldProtect() check. IL2CPP has some internal types and methods that it references by name, so we cannot change those. Additionally, a config file containing target class names is used to further make the obfuscation a bit more targeted. In theory, we could switch this around and instead obfuscate everything except the internal types and methods, but this list would be very long (although finite, so it’s possible).
Here is the rest of the code. IsInternalType() also checks for method names used by MonoBehaviour (the GameObject base class), such as Awake(), Start(), and Update().
void Metadata::ModifyField(FieldDefinition* field)
{
char* namePtr = GetStringFromIndex(field->NameIndex);
std::string name(namePtr);
if (IsInternalType(name))
return;
Hash::Run(namePtr, strlen(namePtr));
printf(" - [field] %s => %s\n", name.c_str(), namePtr);
}
void Metadata::ModifyParameter(ParameterDefinition* parameter)
{
char* namePtr = GetStringFromIndex(parameter->NameIndex);
std::string name(namePtr);
if (IsInternalType(name))
return;
Hash::Run(namePtr, strlen(namePtr));
printf(" - [param] %s => %s\n", name.c_str(), namePtr);
}
void Metadata::ModifyProperty(PropertyDefinition* property)
{
char* namePtr = GetStringFromIndex(property->NameIndex);
std::string name(namePtr);
if (IsInternalType(name))
return;
Hash::Run(namePtr, strlen(namePtr));
printf(" - [prop] %s => %s\n", name.c_str(), namePtr);
}
void Metadata::ModifyMethod(MethodDefinition* method)
{
char* namePtr = GetStringFromIndex(method->NameIndex);
std::string name(namePtr);
if (IsInternalType(name))
return;
if (name.find('.') != std::string::npos)
return;
Hash::Run(namePtr, strlen(namePtr));
printf(" - [method] %s() => %s()\n", name.c_str(), namePtr);
for (uint32_t i = 0; i < method->ParameterCount; i++)
{
ParameterDefinition* parameter = GetParameterDefinitionFromIndex(method->ParameterStart + i);
ModifyParameter(parameter);
}
}
Now let’s run it and save the modified buffer back into the global-metadata.dat file.
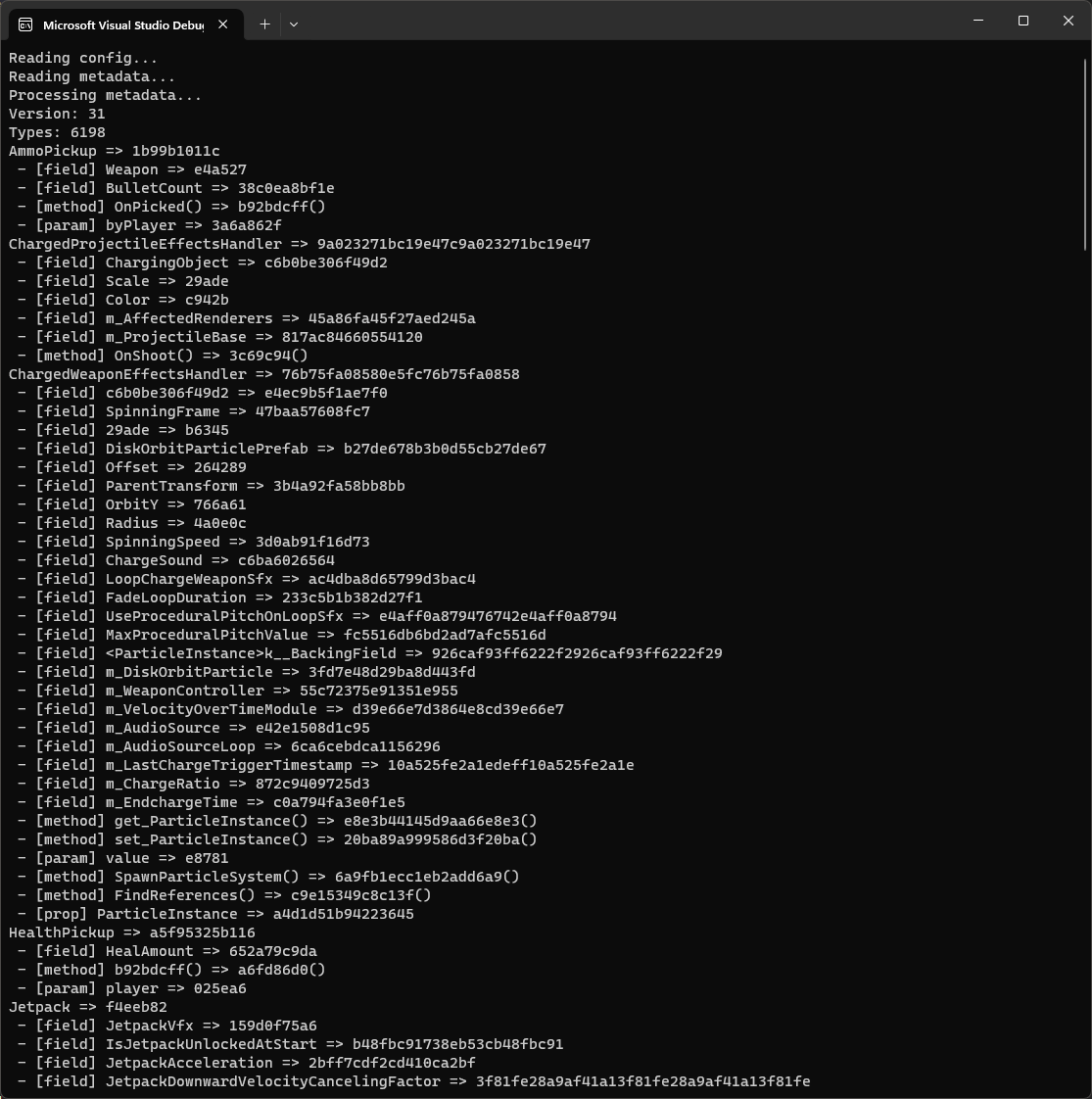
If we now run the dumper and check the generated output, we will see something like this:
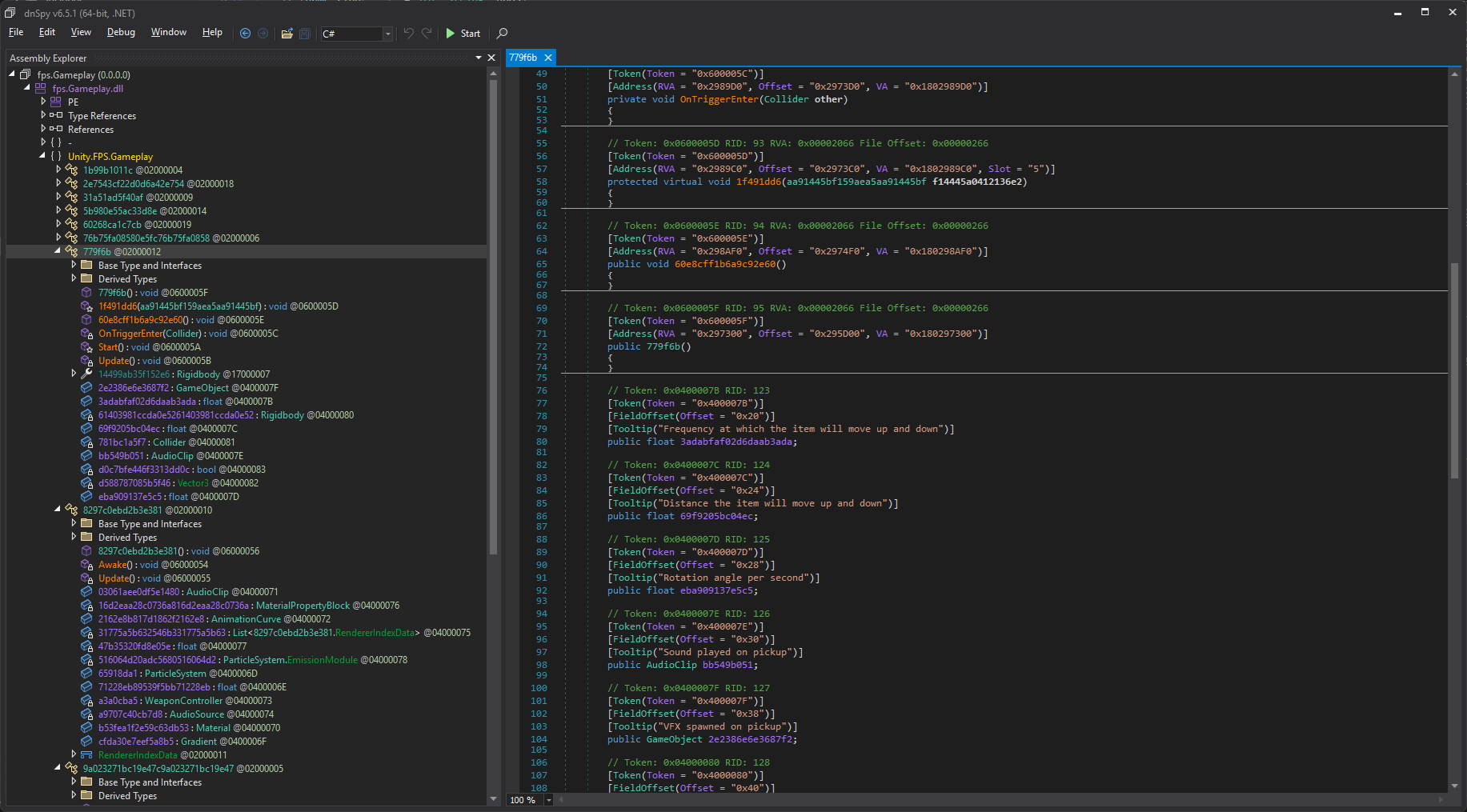
If we try to run the game at this point, it will either be broken or crash right away.
Middleware
Writing the middleware DLL is pretty straightforward. All we need to do is pass through the vast majority of functions to the original DLL. This can be done through forwarded exports or by manually writing function wrappers that will then call the original.
void OnDllAttach()
{
Console::Init();
Console::Print("Loading module...");
Global::GameAssembly = LoadLibraryA("GameAssembly.Real.dll");
if (!Global::GameAssembly || Global::GameAssembly == INVALID_HANDLE_VALUE)
{
Console::Print("Failed to load module");
return;
}
Console::Print("Module loaded at 0x%p", Global::GameAssembly);
}
#define DEFINE_PASSTHROUGH_FUNCTION(return_type, func_name, arg_types, arg_names) \
EXTERN_C DLL_EXPORT return_type func_name arg_types \
{ \
static return_type (*target_func) arg_types = nullptr; \
if (!target_func) \
{ \
target_func = reinterpret_cast<return_type (*) arg_types>( \
GetProcAddress(Global::GameAssembly, #func_name)); \
if (!target_func) \
{ \
Console::Print("Failed to resolve %s()", #func_name); \
return return_type(); \
} \
} \
return target_func arg_names; \
}
DEFINE_PASSTHROUGH_FUNCTION(int, il2cpp_init, (PVOID domain_name), (domain_name));
DEFINE_PASSTHROUGH_FUNCTION(int, il2cpp_init_utf16, (PVOID domain_name), (domain_name));
DEFINE_PASSTHROUGH_FUNCTION(void, il2cpp_shutdown, (), ());
DEFINE_PASSTHROUGH_FUNCTION(void, il2cpp_set_config_dir, (PVOID config_path), (config_path));
/* ... */
Then, in functions where a type or method name is passed in, we first try to execute the original function without hashing anything and if it fails, we use the same hash function that we used previously:
EXTERN_C DLL_EXPORT PVOID il2cpp_class_from_name(const PVOID image, const char* namespaze, const char* name)
{
static PVOID(*target_func)(const PVOID, const char*, const char*) = nullptr;
if (!target_func)
target_func = reinterpret_cast<PVOID(*)(const PVOID, const char*, const char*)>(GetProcAddress(Global::GameAssembly, "il2cpp_class_from_name"));
Console::Print("il2cpp_class_from_name(): %s.%s", namespaze, name);
PVOID result = target_func(image, namespaze, name);
if (result)
return result;
const size_t s1 = strlen(namespaze);
const size_t s2 = strlen(name);
char t1[256];
char t2[256];
if (s1 >= sizeof(t1) || s2 >= sizeof(t2))
{
Console::Print("Buffer too small");
return result;
}
memcpy(t1, namespaze, s1 + 1);
memcpy(t2, name, s2 + 1);
Hash::Run(t1, s1);
Hash::Run(t2, s2);
Console::Print("-> %s.%s", t1, t2);
result = target_func(image, t1, t2);
Console::Print("-> 0x%p", result);
return result;
}
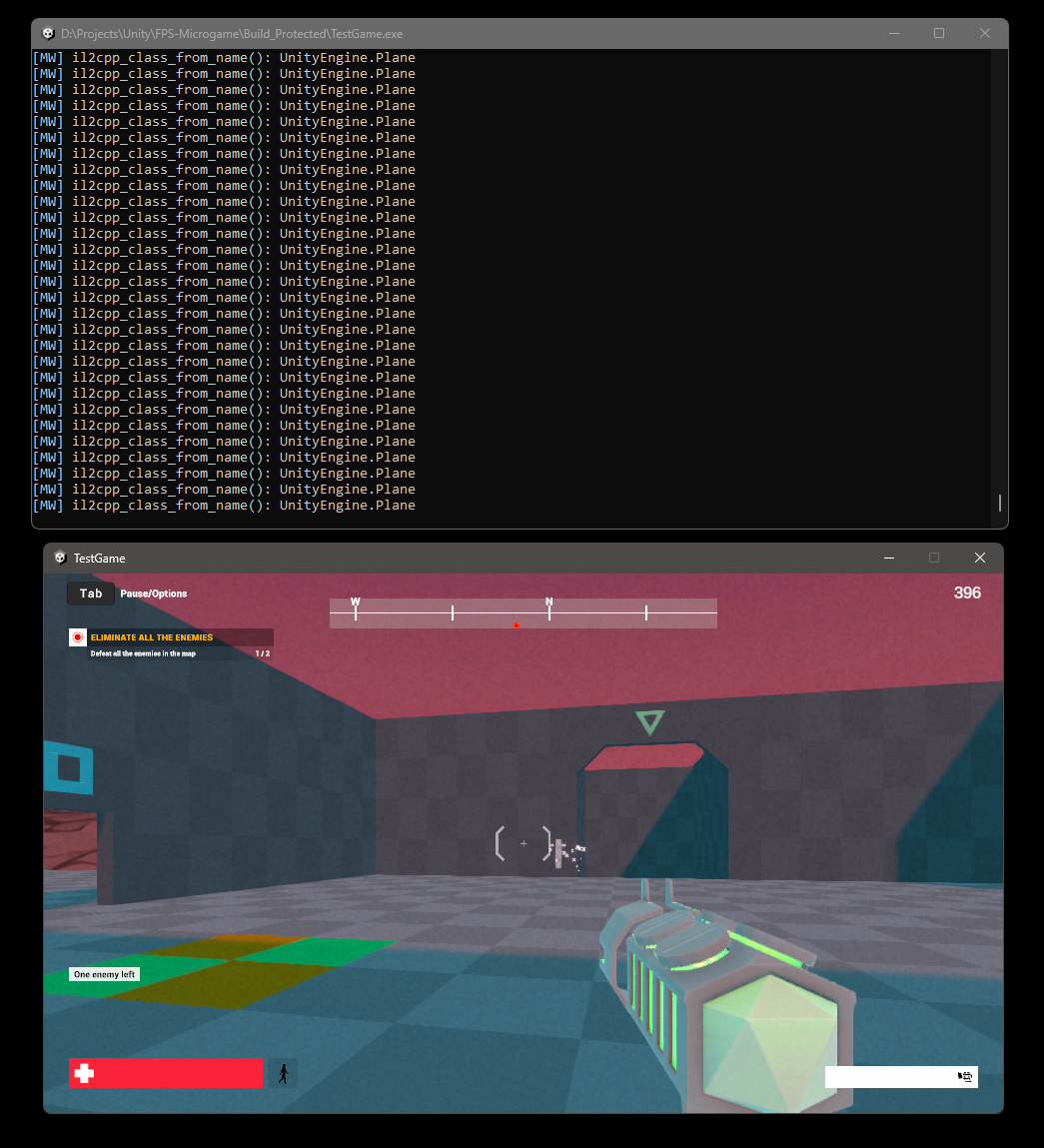
And that’s it. If we now run the game, it will start and work just fine. We can also verify that no weird stuff is going on by checking the logs again.
Possible issues
In my proof of concept, I implemented the hashing only into il2cpp_class_from_name(), as that appeared to be all that was needed. As far as I can tell, more complex projects might require adding hashing to additional functions, such as il2cpp_class_get_field_from_name() or il2cpp_class_get_method_from_name(). That should be relatively easy to implement, though.
Another issue that will take some time to solve, but should be quite straightforward to work on, is the possibility of a hash collision. xxHash should be quite robust, but as I mentioned previously, to save time, I did name replacement with strings of the same length. This means that for very short names with 1-3 letters, the hash will also have just 1-3 letters, increasing the possibility of a collision. To solve this, a fixed length able to store at least a 64-bit number should be used, which requires shifting the entire file around and recalculating all the offsets.
While the names are hashed in global-metadata.dat and therefore will be returned like that when using off-the-shelf tools to dump them, some of them can still be restored through manual analysis. This can be done by parsing the scene and asset files, extracting the names from them, finding the hash function, running those extracted names through it, and then associating those names with the hashes returned by the dumper.
Performance can also be an issue, although from my testing, the il2cpp_*_from_name() exports don’t get called very often. The engine usually calls them once when initializing the class/type and then uses a pointer to reference them. However, there might be some cases where overhead can be introduced, such as when you need to instantiate many classes at once (e.g., AI or particles). Even then, the overhead should be minimal if memory allocations and frees are kept down.
So far, the biggest problem I have noticed is that you can use the same class, field, property, and method name as something internal in Unity. For example, you can create a class called AudioSource in your own namespace, which is perfectly fine. The issue with that is that global-metadata.dat does not store duplicate strings multiple times, so if you replace your own class name with something else, you are replacing all references to AudioSource. This can be solved by tediously going over all the definitions and checking whether multiple of them reference the same string.
And finally, stability. I did all of my testing on the example projects that Unity provides. Attempting to do something similar on projects with extremely large and complex codebases might introduce issues I had no idea about, but I am sure that with enough time and effort something similar can be ironed out to work well.
Other tricks
Those tricks are not IL2CPP-specific and can also be applied to projects using Mono. In some cases, the same concepts can even be adapted for use with entirely different game engines.
Export/Import Obfuscation
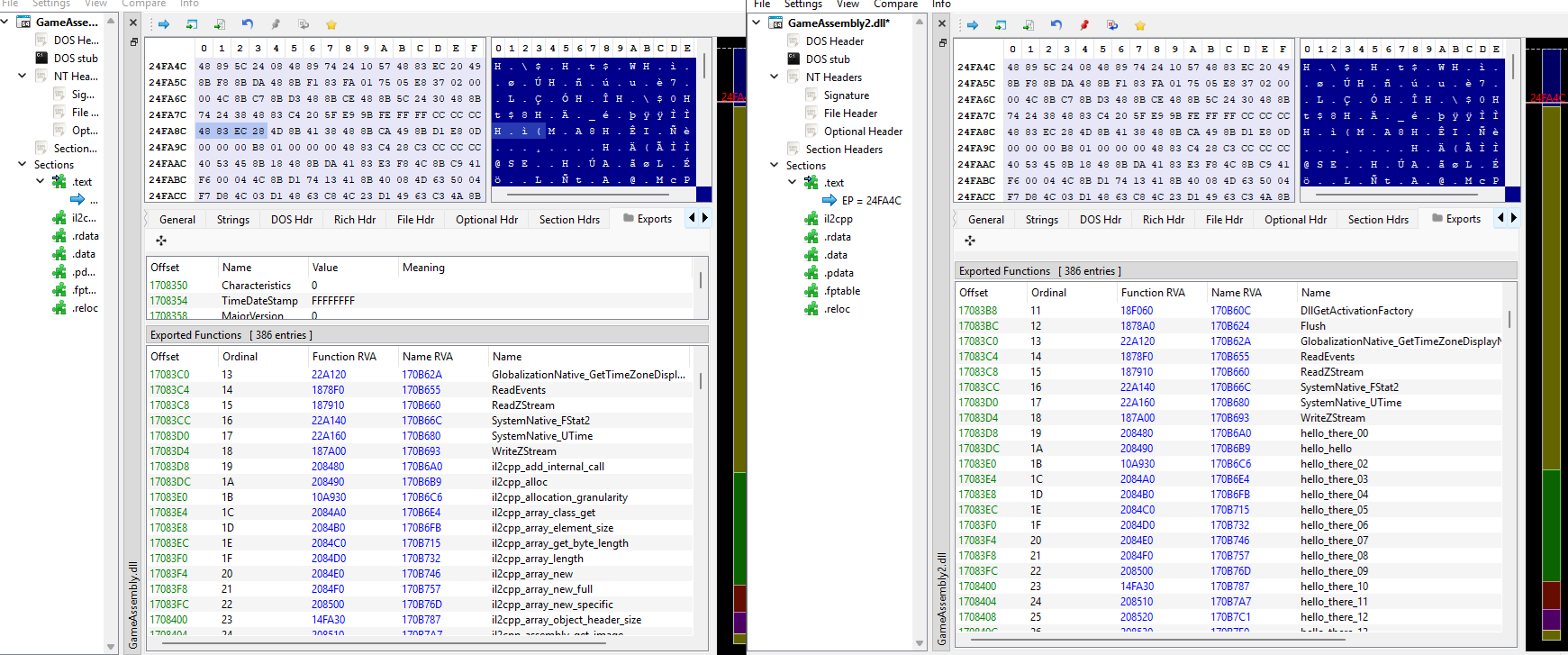
This is straightforward to implement. All we need to do is replace the export names and make corresponding replacements for the associated import names. For example, in our case, we would replace the export names in GameAssembly.dll by modifying its PE headers, and then perform string replacement in UnityEngine.dll, as it dynamically resolves the required imports.
If we wanted to get particularly creative, instead of using random names or a hashing function, we could simply swap the imports around. For example, the function il2cpp_class_from_name could be renamed to il2cpp_array_new, and il2cpp_array_new could be renamed to il2cpp_class_from_name.
Loader stub
We can write a custom loader which, on Windows, would mean replacing the main .exe file (all we need to do is call UnityMain() in UnityEngine.dll). This loader would contain UnityEngine.dll, GameAssembly.dll, global-metadata.dat, and possibly other files as encrypted resources. These resources would only get decrypted once the loader starts, and they would only reside in memory. However, this would require hooking functions such as CreateFile() and ReadFile() since Unity expects these files to exist on disk.
Alternatively, we could use a commercial protector tool like VMProtect, which includes a virtual file system that works exactly like that.
Fake engine version
We can patch out the engine version from the files which will confuse automatic tools. For example global-metadata.dat has also it’s own version depending on which Unity version is used. For Unity 2022.3.55f1 that is version 31. This version is only checked once in GameAssembly.dll and the check can be easilly patched too.
The engine version can also be changed in other places, but that might require mode modifications.
Conclusion
Obviously, the code presented here does not handle all sorts of edge cases (as noted in the issues section). However, given that it took me roughly a few hours to write it, including this article, I’d say it should not be that big of a deal for larger studios to write a proper toolset.
I am not aware of the Unity Enterprise source code access for modification pricing, but unless it’s so extremely expensive that it’s not viable even for large studios, then none of this should really be needed. They could just directly integrate obfuscation into the build process itself and, for good measure, perhaps even change the global-metadata.dat format.
What I don’t really understand though, is why Unity themselves don’t try to make reverse engineering of builds a bit harder. Imagine if you could just check a checkbox in the build settings, and all of the names would be hashed with a random seed, including the ones in scenes and assets. You would then get a file containing a list of the original and hashed names, so in case something goes wrong, you could look up the originals, as with any decent obfuscator.
Anyway, I hope that this article can spark a discussion about possible obfuscation methods a little bit and possibly even inspire someone to write more polished tools.
In case you want to experiment yourself, all of the code used here is in this repository.
Thanks for reading.